「生成AI」のプライバシーの保護と、セキュリティの確保 ~セキュリティフォーラム2024~(前編)
3月6日、中央大学産学官連携・社会共創フロアにおいて、(一社)日本スマートフォンセキュリティ協会、(一社)セキュアIoTプラットフォーム協議会、中央大学研究開発機構・情報セキュリティに関する総合的研究ユニットは、ビジネス活用が進む「生成AI」(Generative AI)におけるプライバシーとセキュリティを主要テーマに「セキュリティフォーラム2024」を開催した。前編では、生成AIの活用における現状と課題、社会への安心・安全な普及・啓発のために求められることなどについて触れた基調講演と特別講演の内容を詳しく紹介しよう。
生成AI時代のセキュリティガバナンスをどう考えるべきか?
冒頭のあいさつでは、SIOTP協議会 理事長 辻井重男氏が、同氏が提唱する「三止揚」や「MELT」(Management、Ethics、Law、Technology)-Upの概念について解説した。

その後、日本マイクロソフトの河野省二氏が、「生成AI時代のセキュリティガバナンス」をテーマに基調講演を行った。生成AIは便利だが、いま企業や組織の中でどのように使われるのかが見えない不安がある。生成に利用されたデータも把握できない環境では安心して利用できないだろう。そこで同氏は、情報セキュリティの基本に立ち返りながら、安心して生成AIを使うための考え方について最初に解説した。

河野氏は、そもそも生成AIの前に「AIとは何か?」という点について触れた。AIは、人間の思考を機械的に実現する技術だ。人間には五感があり、目や耳などから視覚や聴覚など、さまざまなデータがインプットされ、脳でデータを処理して、何がしかのアウトプットを行う。これらを機械で行うには、インプットのためにAIとして認知機能(Cognitive)が必要だ。ここでAIに必要なのは人間と同程度の課題解決の能力「Human Parity」である。
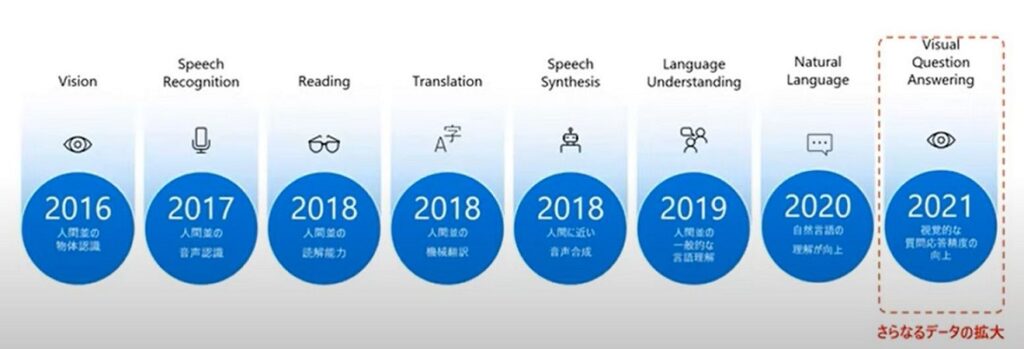
直近のAIの急速な進化の流れをみていくと、2016年ごろからビジョン技術が発達し、人間並みの物体認識が可能になり、データ収集に役立てられるようになった。2017年になると人間並みの音声認識が行えるようになった。ただし同音意義語の区別は難しかった。ところが2018年にはリーディング技術が向上し、人間並みの読解能力になってきた。ある程度、単語の意味が理解できるようになると、人間並みの機械翻訳に近づき始めた。この頃からインプット側のデータを正しく判別できるようになってきた。
しかし2018年ごろから音声合成が発展してきたことが、次の重要なターニングポイントになった。現在のようにAIが大きく伸展してきた背景には、人間のイントネーションに近い形での発話できるようになり、AIが自身で言葉をつくって、自給自足のデータをインプットして学習できるようになったことが挙げられる。これにより入力速度が高速になり、2019年以降はLLMやデータ基盤が飛躍的に進展し、人間並みの一般的な言語理解や自然言語の理解が向上していったのだ。 そして2021年には、VQA(Visual Question Answering)が登場し、さらなるデータ拡大が始まり、目前にあるすべてものを自然言語で表現することが可能になり、ある状態を見た瞬時に何か判断して、それに対応したアウトプットが出せるようになった。
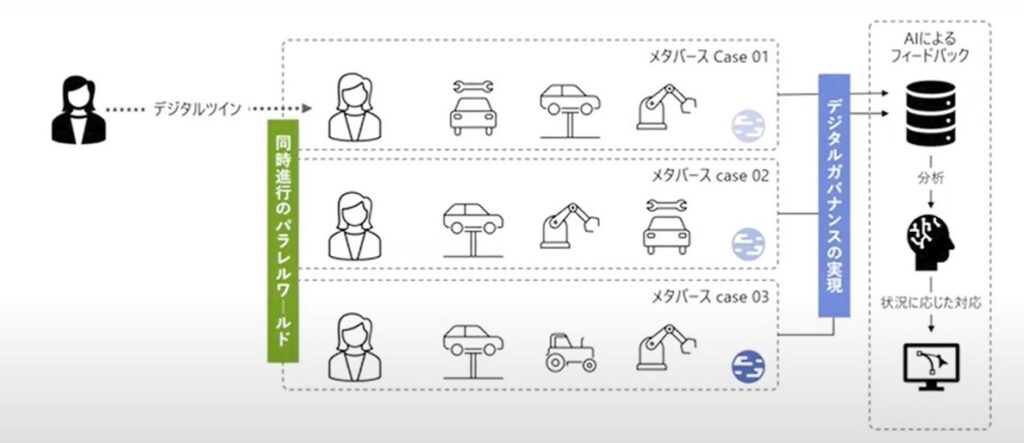
そうなると、いろいろなデータからデジタル的に何かを複製し、それをサイバースペースで産業用途の「インダストリアル・メタバース」として使えるようになる。たとえば、機械や工場をデータ化してデジタルツイン化し、ソフトウェアとして動かしたデータをAIで分析してフィードバックすればプロセスの改善に役立つ。このプロセスを最短のデジタルスピードで実現するには、メタバースのパラレルワールドを同時進行させ、多様なパターンから理想的な環境を選択したり、トラブルを予兆したりすればよい。これを最終的にリアルな工場設計に反映させるわけだ。
ここまでがデータのインプットからの認知機能の流れだが、処理プロセスでコアとなるのがAIモデルである。マイクロソフトではLLMを開発しているが、英語と日本語では文法が異なるため、最適モデルも異なってくる。これを共通モデルで実現するようにデータを蓄積中だ。このプロセス部分は、どれだけデータを一元化できるかという点にかかっている。そして今回のイベントのテーマにもなっている生成AIだが、これはアウトプットのための技術となる。

いま生成AIは「情報抽出系」「文脈理解系」「チェック系」「翻訳系」「分類系」などにカテゴライズされる。要約や翻訳や校正など、これらの一部の処理は、以前より統計ベースでも定型的に処理できるケースもあった。ただルールに則って何かを作っていくような「文章生成系」や「インサイト系」などの分野は、新たにできるようになった分野だ。

たとえば、プレゼンテーションのPPTをつくるときは、最初に内容を話してAIでワードに落とし、そこからPowerpointでスライドをつくるように指示すると簡単にPPTを作成できてしまう。こうすれば生産性も上がるし、指定時間内で説明できるPPTができあがる。さらに生成AIのメリットとして挙げられるのは、何度でも繰り返して生成し、あとからブラッシュアップできることだ。こういったコンテンツ生成だけでなく、いまはコードも手順書を示せばダイナミックに組める時代になってきている。さらに「セマンティック検索」(意味を考慮した検索)も実現できる。
たとえば、カーナビである場所を指定したあとに、食事がしたくなったら、AIに対して「こういうモノを食べたい」といったことを話しかければ、AIが「この場所が良い」と、会話のコンテキストからダイナックにオススメとして示し、途中からそこに導いてくれる。このように、さまざまな業態の多様な業種でAIの活用が進んでいるのだが、最近目立つのが製造業での活用だ。もともと製造業は現場から大量データが吐き出されるし、データが蓄積されており、品質面での改善に役立てられるからだ。
とはいえ一方で、製造業ではAIを使うことに躊躇する向きも多い。そこで何かトラブルがあってもすぐに対応できる「Responsible AI」を構築し、心配なときにいつでも確認できる環境を構築すればよいだろう。これは「AIが何をしているのかを判断が可能な状態にする」ということだ。情報セキュリティリスクの観点からは「資産を常にコントロールできる状態にすること」になる。
Microsoft CoPilotのWordでは、文章のひな型を生成したときに、もし会社の機密情報が紛れ込んでいれば、「Confidential」というラベルが自動的に付くようになっている。Windows10以降は、ファイルごとに多くのメタデータで管理できるようになったからだ。これらのデータを一括管理するツールも用意されている。
このようにAIを最大限に活用するには、局所的ではなく、組織的に「Get AI-Ready」のIT基盤を用意する必要があるだろう。そのためにはDXによって、すべてのデータを記録しておき、それらの記録をベースにした組織のBIを形成したうえで、組織のインテリジェンスを最大限に発揮できるAIの仕組みを構築する。具体的にはDXでデジタル化されたデータをGraphデータベースで管理する。このデータベースは、データ同士の関係性(ネットワーク)をもとにデータの意味(セマンティック)を生成してくれるものだ。たとえば、あるデータが他のデータを改変したものであるといったことが関連づけられる。

Graphデータベースを作るには、資産管理やID管理のデータベースを用意し、それらの連携ができるようになると、より良い関連性が生まれる。いまは外部のデータストレージでもデータの関係性をつくれる。たとえばMicrosoft Azureだけでなく、AWS S3のセマンティックのインデックスだけを集められる。ここでResponsibleな(責任ある)AIとするには、AIインターフェースを介する各種データベースやアプリ、AIエンジンへのデータの流通を暗号化したり、OpenID Connectなど個人のアカウントに紐づくトークンとセマンティックを連携したりする方策が考えられるだろう。 Microsoft Graphのデータベースでは、常にデータのセマンティックを作っているため、何か異なる関係性が検出されると、「Defenderシリーズ」が異常を検出し、自動で構成変更がなされ、内部システムだけでセキュリティが一括で完結できる。さらに外部データを取り込む際にはMicrosoft Fablic経由での連携も可能だ。ただし、こういったシステムを一企業が構築するのは大変だし、手間もかかる。そこでMicrosoftでは安全な環境で、簡単に環境構築を行えるビジュアルライクなAzure AI Studioを提供し、自由に使えるようにしているところだ。

このようにAIがどこでどのように使われているかを、資産管理とID管理のデータの側面、それらを関連づけるGraphデータベースの側面から見ていくことにより、即時にデータを把握できるようになり、何か異常があっても修正できる体制になる。今後は、そういった情報を基にして、いかに早くハードウェアの構成変更できるかということがポイントになるだろう。いま製造業は十分にデータがあるため、AIが最も利用できる分野だ。そのための安全な環境を構築していただきたい。
スマートフォンなどのネット上の偽・誤情報に関する総務省の主な取り組みと対策
続いて総務省の恩賀 一氏が、「デジタル空間における情報流通の健全性確保の在り方に関する検討会」で報告された偽・誤情報を取り巻く現状と課題などについて、特別講演で紹介した。

近年、SNS(LINE、X、Meta)や生成AIなどの普及に伴い、スマートフォンなどで、インターネット上の偽・誤情報が流通・拡散し、深刻化している状況だ。特に国内では、年明けに起きた能登半島地震の偽・誤情報がクローズアップされた。ユーロポール(欧州刑事警察機関)の報告書では「2026年までにオンライン上のコンテンツの約90%が生成AIでつくられたものになる」という衝撃的な予測もある。
生成AIのコンテンツがインターネット上で広がる背景の仮説として「アテンションエコノミー」の影響があるという。ネット上に膨大な情報が流通する一方で、人々の消費時間は有限であり、事実に基づく正確な情報だけでなく、過激なタイトルや内容、憶測で作成された情報などによって利用者を刺激し、より多くのアテンション(注目・関心)を集めて、金銭的な対価を得ようとする動きだ。
またSNSの進展に伴い、自分の価値観に近いものが表示されやすい「フィルターバブル」や、自分が発信した意見に似た意見が返って意見が増幅される「エコーチェンバー」と呼ばれる現象も発生している。そういった状況に気づかず、適切な判断を下せずに、結果として社会経済の混乱や、民主主義への悪影響を及ぼす可能性も指摘されている。これに伴い、インターネット上に偽・誤情報などの流通が顕在化してきているという。 一方で生成AIやディープフェイク技術を使った巧妙な偽・誤情報も増えている。近年の世界各国の事例は以下の通りだ。
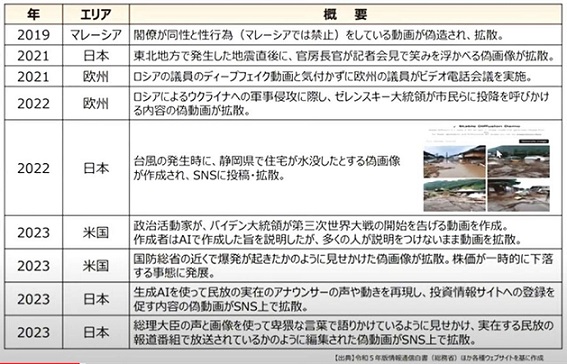
このような状況でG7やダボス会議でも「生成AIの急速な進展がリスクをもたらしている」という認識で一致している。そのような中で、日本では今年の元旦に発生した能登半島地震で、大量の偽・誤情報が拡散された。それを日本ファクトチェックセンター(JFC)で整理したり、その類型別の流通状況を東大がXのデータを中心に検討している。ここでは特に金銭的なインセンティブ(閲覧数稼ぎ)やイデオロギーで多様な偽誤情報が見られた。 総務省でも発災の翌日から地震のアカウントで注意喚起を行うとともに、SNSなどの主要なプラットフォーム事業者に対して、利用者規約を踏まえた適正な対応を要請した。その後、総理大臣や総務大臣も会見でフォローし、さらにインターネットなどで注意喚起を促した。これにより各プラットフォーム事業者が、モニタリングの強化やラベル付け、通報による削除などを実施。現在、総務省では各事業者に対してヒアリングを実施中で、LINEヤフーでは、偽・誤情報の大半が「人工地震情報」であったと報告している。現在はGoogleやMetaなどに対してもヒアリングを行っているところだ。

また総務省では、令和5年度補正予算を利用して、ディープフェイク対策技術の開発・実証を進めていく。これまでは人物に関するディープフェイクが中心だったが、今回の地震を受けて、街並みや風景についても判別できるようにするという。一方、情報コンテンツや発信者の信頼性などを確保する技術の導入も促進していく。たとえばコンテンツに対して来歴した発信者に関する情報を付与するなどの技術実証を支援する方向だ。

実は、総務省は今回の地震が発生する前から「デジタル空間における情報流通の健全性確保の在り方に関する総合的な対策」を検討してきた。プラットフォーム事業者による自主的な取り組み、AI・国際戦略、ICTリテラシーの向上、安心・安全なメタバースの実現を骨子とし、今年の夏頃までに幅広い有識者の検討会により、一定の報告書をまとめてもらい、関係省庁やオブザーバー団体とも連携しながら進めていく方針だ。

大まかな方向性としては、個人情報・プライバシー情報の保護と、人の認知領域の保護に共通性があることから、具体的な方策として参考になったり、人と社会の文脈からコグニティブ(認知)セキュリティの研究も進んでおり、ネット上の偽・誤情報対策とサイバーセキュリティ対策の近似性を踏まえた社会的な仕組みづくりも考えていく方向だ。たとえば、情報の拡散前の対策を中心とした個人レベルのPrebunkingの切り口や、各プラットフォーム事業者に対するシステムレベルでの介入の方向性も示唆されている。 総務省では、こういった検討と施策の推進によって、インターネット上の偽・誤情報の対策を早急に進めていく構えだ。






